Build dictionaries for any language
dictpress is a free and open source, single binary webserver application for building and publishing fast, searchable dictionaries for any language.
Download
dictpress is a free and open source, single binary webserver application for building and publishing fast, searchable dictionaries for any language.
Examples dictionaries:

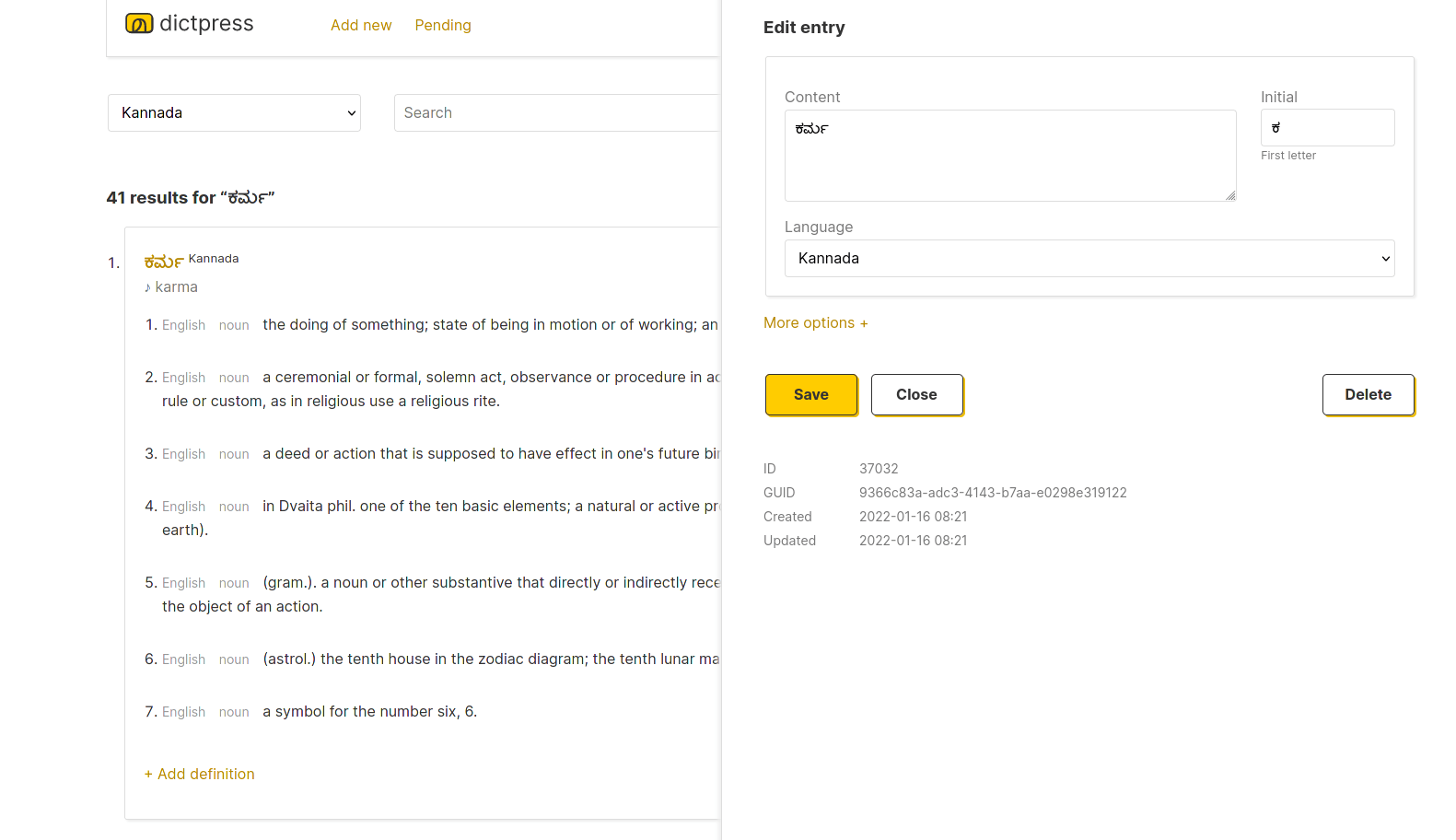
DictPress is language agnostic and has no concept of language semantics.
It stores all data in an SQLite database file in just two tables entries and relations.
To make a universal dictionary interface possible,
it treats all dictionary entries as UTF-8 strings that can be searched with SQLite's fulltext capabilities
on tokens alongside them. The tokens that encode and make the entries searchable
can be anything—simple stemmed words or phonetic hashes like Metaphone.
DictPress bundles a Snowball stemming algorithm library which supports [arabic, danish, dutch, english, finnish, french, german, greek, hungarian, italian, norwegian, portuguese, romanian, russian, spanish, swedish, tamil, turkish].
For languages that do not have fulltext tokenisation, search tokens can be generated externally using any algorithm and plugged in. For example, Olam uses MLPhone, a simple Metaphone like phonetic hashing algorithm that allows Malayalam words in the dictionary to be searched by how they sound.
See this article for historical context on the project.